🗒️大模型中的上下文窗口
type
status
date
slug
summary
tags
category
icon
password
了解大模型的上下文窗口(Context Window)机制,不仅对开发者来说非常重要,对于使用者来说同样重要,例如我们在使用ChatGPT、文心一言、KIMI等通用型AI助手时能根据需求一次性输出1万字的长文,但是现实却只输出几千个字,如果我们知道上下文窗口的概念,那么我们就知道可能哪些因素是和大模型相关,哪些是和AI应用的开发者相关。
一、背景
上下文窗口(context window)是指语言模型在进行预测或生成文本时,所考虑的前一个词元(token)或文本片段的大小范围。
在语言模型中,上下文窗口对于理解和生成与特定上下文相关的文本至关重要。较大的上下文窗口可以提供更丰富的语义信息、消除歧义、处理上下文依赖性,并帮助模型生成连贯、准确的文本,还能更好地捕捉语言的上下文相关性,使得模型能够根据前文来做出更准确的预测或生成。
二、上下文窗口受限的原因
通常所说的大模型是指大语言模型(Large Language Model,LLM),其模型结构一般基于 Transformer 进行改进而来。Transformer 源自于 2017 年 Google 发表的著名论文"Attention Is All You Need”。

它的结构包括两部分:Encoder(编码器)和Decoder(解码器)。Encoder 与 Decoder 大致都包含以下层,每一层都有特定的功能,下面为 Encoder(编码器)各层的简单介绍:
- 输入嵌入层(Input Embedding Layer):将输入文本的词或标记转换为向量表示,以便模型能够理解它们。
- 多头自注意力层(Multi-Head Self-Attention Layer):帮助模型捕捉输入序列中词与词之间的关系,使模型能够了解上下文信息。
- 前馈神经网络层(Feed-Forward Neural Network Layer):对多头自注意力的输出进行进一步的特征提取和变换,以增加模型的表示能力。
- 归一化层(Layer Normalization Layer):规范化每一层的输出,有助于训练过程的稳定性。
Transformer多头注意力(Multi-Head Attention)
1. 我们有一个查找嵌入层,用于接收词元作为输入,并返回大小为(1,d)的向量。因此,对于一个由n个词元组成的序列,我们得到大小为(n,d)的文本嵌入矩阵X,然后将其与位置正弦嵌入相加。
2. 多头注意力层旨在为词元序列计算新的嵌入表示,该词元序列可以被视为对原始文本编码X,但需要:
- 根据词元间相对于上下文的重要性进行加权,
- 根据词元的相对位置进行加权。
3. 我们使用h个注意力头对嵌入矩阵X(n×d)进行并行处理。为了使所有的注意力头都得到Q、K和V,我们需要对X进行线性投影,将其分别投影到k、k和v维度。为此,可以通过将X分别与形状为(d,k)、(d,k)和(d,v)的h个矩阵相乘来实现。你可将其理解为用(n,d)乘以(h,d,k)、(h,d,k)和(h,d,v)。
4. 注意力头返回大小为(n,v)的h个注意力分数矩阵。然后,我们将来自所有注意力头(n,h*v)的片段进行连接,并对其进行线性投影,为后续步骤做准备。

Transformer缩放点积注意力(Scaled Dot-Product Attention)
Q、K、V是X的3个线性投影,大小分别为(n,k)、(n,k)和(n,v),通过乘以每个注意力头的可学习权重(learnable weight)获得。
通过计算Q和K(转置)之间的距离(点积),我们得到了注意力分数。将矩阵(n,k)与(k,n)相乘,得到矩阵(n,n),然后我们将其与掩码矩阵相乘,以将一些词元置零(在解码器中需要)。接下来,我们对其进行缩放,并应用softmax函数,使注意力分数范围在0到1之间。这样,我们就得到一个形状为(n,n)的矩阵,其中表示第i个和第j个词元之间的相对注意力分数(0-1之间),这展示了这些词元在给定长度为n的特定上下文中有多“接近(close)”。
然后,我们将这个注意力分数矩阵(n,n)乘以大小为(n,d)的“值(value)”V,以获得由这些相对注意力分数加权得到的文本嵌入。


Transformer的复杂度和上下文长度
2个矩阵乘法(a,b)*(b,c)的复杂度为O(a*b*c)。
为简单起见,我们假设k*h = O(d),并利用这个假设来推导注意力机制的复杂度。
注意力层的复杂度由两部分组成:
1. 线性投影得到Q,K,V:大小为(n,d)的嵌入矩阵乘以h个可学习矩阵(d,k),(d,k)和(d,v)。因此,复杂度约为O(nd²)
2. 将Q与变换后的K相乘,然后再乘以V:(n,k)*(k,n)=(n,n),以及(n,n)*(n,v)=(n,v)。复杂度约为O(n²d)。
因此,注意力层的复杂度为O(n²d + nd²),其中n是上下文长度(输入词元的数量), d是嵌入大小。从这里我们可以看出,注意力层计算的复杂度与输入词元数n和嵌入大小d相关,分别是二次方关系。
当d>n时(例如,在LLaMa中,n=2K,d=4K),O(nd²)这个因素非常重要。
当n>d时(例如,在使用n=65K和d=4K进行MosaicML训练时),O(n²d)这个因素非常重要。
提醒一下,二次方增长的情况有多糟糕:
2000²=4000000, 100000²=10000000000
举例说明一下二次方复杂度是如何影响模型训练成本的。LLaMa模型的训练估计价格约为300万美元(https://matt-rickard.com/commoditization-of-large-language-models-part-3),具有650亿个参数,2K的上下文长度和4K的嵌入大小。预估时间大部分是GPU训练时间。如果我们将上下文长度从2K增加到100K(增加了50倍),训练时间也会增加大约50倍(由于上下文更大,迭代次数较少,但每次迭代的时间更长)。因此,以100K上下文训练LLaMa模型的成本约为1.5亿美元。
对该计算稍作详细说明:
假设token数量为n时,注意力的复杂度为O(n²d + nd²),需要进行M次迭代来进行训练。如果我们将上下文长度从n增加到p*n,由于上下文长度变大,所需的迭代次数将变为M/p(这里简单假设它是线性的,实际情况可能会高点或低点,具体取决于任务)。现在我们有两个方程式:(1)n的复杂度为M * (n²d + nd²)(2)pn的复杂度为M/p * ((pn)²d + (pn)d²)经过一系列简化和除法,得到比值(2)/(1)的近似为 (d + p*n)/(d + n)。如果 d << n,将n增加p倍将导致迭代次数增加约p倍。如果 d ~ n,将n增加p倍将导致迭代次数增加约p/2倍。
Transformer位置向量
目前主流的大模型通常只提供一个有限且较短的预定义上下文窗口。例如,LLaMA2 允许输入最多4096个 tokens。当输入超过该限制时,由于模型没有在预训练中见过超出上下文窗口的新的 token 位置,其性能会显著下降。
由于 Transformer 自身具有置换不变性(Permutation Invariance),无法直接捕获每个词在序列中的位置信息,因此使用位置编码将序列中元素顺序信息融入Transformer成为一种常见做法。根据位置编码表示的是序列中元素的绝对位置信息还是相对位置信息,业界将位置编码分为绝对位置编码(Absolute Position Encoding,APE)和相对位置编码(Relative Position Encoding,RPE),其主要区别如下图所示(左图表示 APE,右图表示 RPE)。
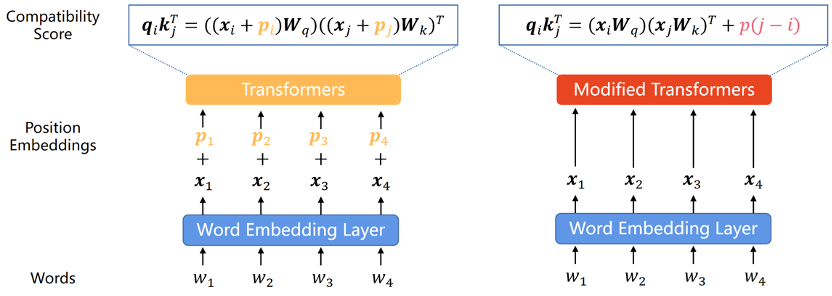
绝对位置编码
在原始的 Transformer 论文中,位置编码是通过正弦和余弦函数生成的,这些函数将位置映射到模型的表示空间中。Transformer 的作者猜想这种正弦位置编码可以有效外推,但是后来的研究成果否定了这一猜想。尽管如此,作为 Transformer 的第一个 PE,正弦 APE 对之后的 PE 产生了重大影响。
为了增强 Transformer 模型的外推能力,研究人员要么通过随机位移将位移不变性融入正弦 APE 中,要么生成随位置平滑变化的位置嵌入并期望模型能够学会推断这一变化函数。基于这些思想的方法展现出比正弦 APE 更强的外推能力,但仍无法达到 RPE 的水平。原因之一是,APE 将不同的位置映射到不同的位置嵌入,外推意味着模型必须推断出不曾见过的位置嵌入。然而,这对于模型来说是一项艰巨的任务。因为在广泛的预训练过程中重复出现的位置嵌入数量有限,特别是在 LLM 的情况下,模型极易对这些位置编码过拟合。
相对位置编码
由于 APE 在长度外推上的表现难以令人满意,而 RPE 天然地由于其位移不变性具备更好的外推能力,并且人们普遍认为上下文中单词的相对顺序更重要。近年来,RPE 已成为编码位置信息的主要方法。
早期的 RPE 来自于对正弦位置编码的简单修改,并常常结合裁剪或分箱策略来避免出现分布外的位置嵌入,这些策略被认为有利于外推。此外,由于 RPE 解耦了位置和位置表示之间的一对一对应关系,因此将偏差项直接添加到注意力公式中成为将位置信息集成到 Transformer 中的一种可行甚至更好的方法。这种方法要简单得多,并且自然地解开了值(value)向量和位置信息的纠缠。然而,尽管这些偏置方法具有很强的外推性,但它们无法表示 RoPE(Rotary Position Embedding,旋转位置编码)中那样复杂的距离函数。因此,尽管 RoPE 的外推性较差,但由于其优异的综合性能,成为近来 LLMs 最主流的的位置编码。
Transformer训练阶段和推理阶段的区别
在训练过程中,Transformer可以并行计算;而在推理过程生成文本时,Transformer需要按顺序逐步生成,因为下一个词元依赖于前面的词元。实现推理的直接方式是逐步计算注意力分数,并缓存以前的结果供未来的词元使用。
超长上下文的大模型部署推理的时候,往往会面临如下性能挑战。
- 推理时间变长
从上面的 Attention 的计算公式可以看出,Attention 进行了点积的运算,其时间复杂度为 L(序列长度)的平方。也就是说大模型在推理的时候,输入的序列长度越长推理时间越多。所以超长上下文的大模型需要更多的推理时间,这会带来用户体验上的损失。
- 推理显存空间变大
大模型在持续推理的过程中,需要缓存一个叫做 KV Cache 的数据快,KV Cache 的大小也与序列长度成正比。以 Llama 2 13B 大模型为例,一个 4K 长的序列大约需要 3G 的显存去缓存 KV Cache,16K 的序列则需要 12G,128K 的序列则需要 100G 显存。
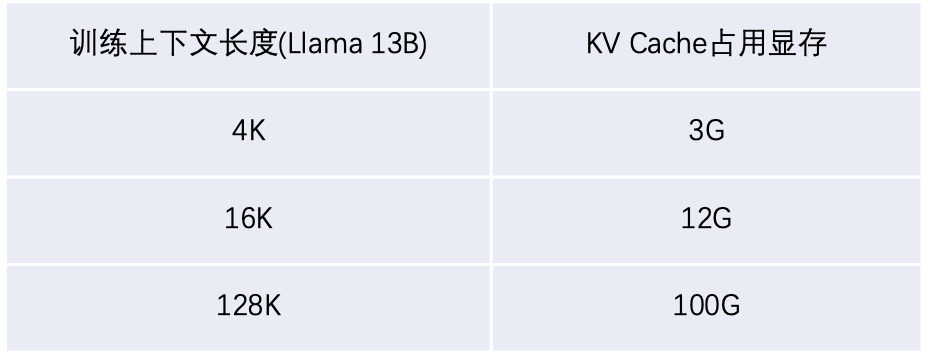
超长上下文的大模型需要更多的 KV Cache 存储空间,但是 GPU 显存非常珍贵,比如 A100 也只有 40G 或 80G 显存两个版本,这对本来就比较紧张的 GPU 显存来说是一个很大的挑战。
上下文窗口长度限制总结
综上所述,大模型的上下文窗口长度限制有以下几种原因:
- 计算资源限制:处理和生成大量的token需要大量的计算资源和时间,上下文越长,模型推理时所需要的显存空间越多,推理时间越长。
- 质量控制:生成文本的长度越长,模型在保持上下文一致性方面的难度就越大,这可能导致输出的文本出现重复、不相关或逻辑不连贯的内容。通过限制token数量,模型可以更好地集中生成高质量的内容,确保每个部分的信息都是相关且有意义的。
拓展大模型上下文长度的方式
论文The What, Why, and How of Context Length Extension Techniques in Large Language Models – A Detailed Survey 对现有大模型上下文长度拓展方法做了详细的总结:

主要将其分为了Interpolation(插值)和Extrapolation(外推)技术:
- Interpolation: 融合不同来源或者不同上下文的信息,以提高预测的准确
- Extrapolation: 将模型的理解范围扩大到其训练的上下文长度之外。
其中:
- zero-shot: 表示先对模型进行改造,再重新训练,使模型自身具备长文本分析的能力;
- fine-tune: 表示对已经训练好的不支持长文本的模型进行改造,再进行微调;
大致可以简单分为以下几种主要的方式:

综上所述,扩展大模型的上下文长度,一般思路如下:
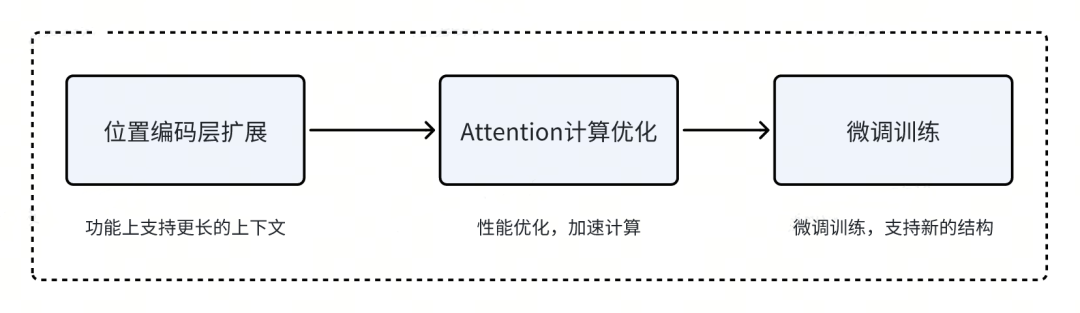
- 首先通过对位置编码层进行改造,使其支持更长的上下文。
- 为了取得更好的推理性能,还需要对 Attention 计算进行优化。
- 进行微调训练,让大模型适应新的模型结构。
参考文章
- Twikoo
Last update: 2024-08-06
-- 感谢您的支持 ---